[总结]MIT-6.824分布式课程-Mapduce实验
MIT 6.824分布式系统课程,是一门著名的讲解分布式系统设计原理的课程。通过课程讲解和实验结合来学习分布式系统设计原理,实验和课程安排见课程表。
前言
我为什么要学习这个课程?之所以会接触到这门课程,是之前在表示对分布式系统感兴趣时一位基友介绍的,由于种种原因并没有开始学。直到最近,开始研究分布式缓存系统的设计才重新开始。有读过笔者之前的文章可能知道,笔者对redis的研究内容比较感兴趣,后面对redis如何做分布式缓存比较感兴趣,于是开始查资料,后来发现etcd在这方面也很强,在学习etcd过程中又了解到了到了raft协议,接着就查到了这门课程中有介绍Raft协议的论文以及相关的实验,刚好得知2020年春季的课程有官方版的视频且被热心网友分享到B站了,再加上完成实验需要用go语言来实现,基于学习分布式系统设计原理和实践go语言的目的,于是就开始学习这门课程。
实际上,etcd和redis是完全不一样概念的东西,etcd主要用于分布式锁以及集群核心配置,核心特性是高可用;而Redis是内存型数据库,目的是做分布式缓存,保存数据。
准备资料
学习这门课程,是先阅读了课程主页的介绍,接着根据课程表去学习,课程表里说明了先阅读论文后再去上课(或者看视频),要先看论文后再去看视频,否则看视频时教授在讲什么都不知道。
上课步骤就是:读论文->看视频->做实验。
MapReduce简介
通过学习论文、课程视频以及完成了实验,对MapReduce有了个初步的认识,在这里总结一下我的理解。
MapReduce,本质就是一种编程模型,也是一个处理大规模数据集的相关实现。之所以会有这个模型,目的是为了隐藏“并行计算、容错处理、数据分发、负载均衡”,从而实现大数据计算的一种抽象。
MapReduce的编程模型:
-
map:接收一组输入的key/value键值对,处理后生成一组被称为中间值的key/value键值对集合。
-
reduce:输入是map生成的key/value键值对集合,合并中间值集合中相同key的值。
整个处理过程的抽象过程如下:
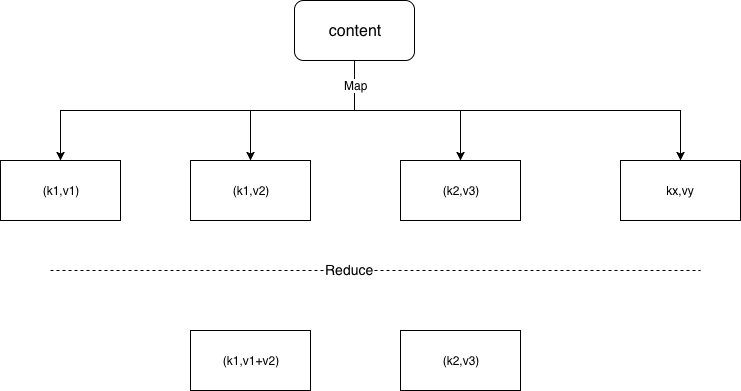
在分布式系统中,除了程序以外还有很多需要考虑的问题,比如并发、容错处理等等,对于分布式的MapReduce,执行概览看下面这幅经典的流程图:
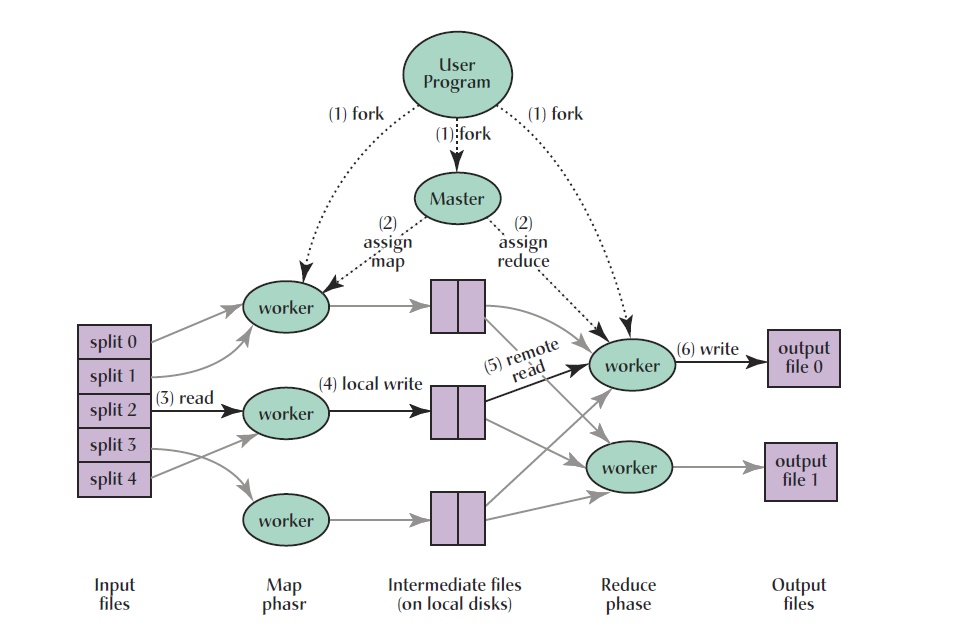
从图里可以看到,Map和Reduce程序分布在多台机器,取出分片数据来处理,数据可以被多台机器并行地处理,而如何分发数据及程序的管理由Worker和Master组成。执行的流程大致如下:
-
系统会启动一个或多个Master,需要执行任务的机器启动Worker来处理任务。Master主要职责是分配任务给Worker,Master可以随机选择空闲的Worker来分配任务,或者Worker主动向Master请求任务;
-
获得map任务的Worker,读取数据分片,生成一组key/value键值对的中间值集合,并将数据写到本地文件,这里每个map任务数据分为R份(Master创建reduce任务的数量),通过用户定义的分区函数(如hash(key) mod R)决定将key存在哪个文件;
-
获得reduce任务的Worker,通过远程调用请求数据,数据加载完毕后,对数据进行排序,之后遍历数据,将相同key的数据进行合并,最终输出结果;
-
当所有的map和reduce任务完成了,整个MapReduce程序就处理完毕了,Worker得到处理后的数据,通常会保存在不同的小文件中,合并这些文件之后就是最重要的结果。
以上就是我对MapReduce论文的理解总结,还有其他的本地化、任务粒度、合并和排序程序、性能等等话题,因为在实验里还没很深的印象,所以这里暂不进行说明。
另外要重点关注的是容错处理,如果Master中断、Worker程序崩溃,这些情况要怎么处理?论文里提到的解决方案是将处理结果保存在临时文件中,等到任务真正处理完才写到待输出文件里。
实验完成之路
无法入手
读完MapReduce论文后,去看课程的前两节视频,听懂了大部分,然后兴致勃勃开始做实验。代码拉下来之后,发现根本没法下手,对着实验题和代码苦恼了一个晚上,只知道实验1就是要实现一个分布式的MapReduce,但是看代码已经有了map和reduce函数,根本不知道要做什么,感觉还没开始就要结束了。
反复学习资料
第一次开始做实验失败之后,花了几个晚上将论文反复看了两遍,再回去看视频,在第二次的学习里,印象更加深刻了,再反复看题目的说明,说明里提到每次修改完程序后,都要执行test-mr.sh,里面包含了很多测试用例,只要通过了所有测试用例,那么实验就算完成了。于是去看测试用例文件,再结合题目描述,终于知道要做什么了。
测试先行,阅读test-mr.sh可以发现,里面主要包含了5个测试用例:单词计数mapreduce、索引mapreduce、并行map、并行reduce、程序崩溃。比如单词计数,检查的步骤是先运行mrsequential.go输出一个文件mr-correct-wc.txt,接着启动mrmaster和mrworker,得到结果后合并为mr-wc-all文件,比较两个文件内容一样就说明通过该用例了。那么要完成实验要,可以先看看mrsequential.go里面做了什么,写一个分布式程序去实现mrsequential.go的功能。
只要完成了以上的5个测试用例,实验就算完成了,而实际上map和reduce程序已经实现好了,那么需要做的是实现论文里提到的master和worker:
1、如何分配任务?map和reduce任务如何分配?(用例1、用例2)
2、如何实现并行处理?(用例3、用例4)
3、怎么判断Worker崩了?Worker失败后,如何恢复,如何处理正在处理中的任务?(用例5)
4、任务处理完成后,结果如何处理?
5、Worker和Master之间的通信通过rpc通信,如何维持两者间的状态?
理清了需求是要做什么以后,接下来就是设计和编码了。
系统设计
只要是程序,设计起来都不外乎数据结构和算法,对于这个实验而言,也是如此。
数据结构
定义Master和Task的数据结构如下:
type Master struct {
nReduce int
nMap int
mapTasks []Task
reduceTasks []Task
state int // MASTER_INIT;MAP_FINISHED;REDUCE_FINISHED
mapTaskFinishNum int
reduceTaskFinishNum int
}
type Task struct {
State int // TASK_INIT;TASK_PROCESSING;TASK_DONE
InputFileName string
Id int
OutputFileName string
TaskType int // MAP_TASK;REDUCE_TASK
NReduce int
NMap int
StartTime int64
}
实现流程图
根据对论文以及实验题目的理解后,设计Master和Task两个结构体,要实现的功能如下图:
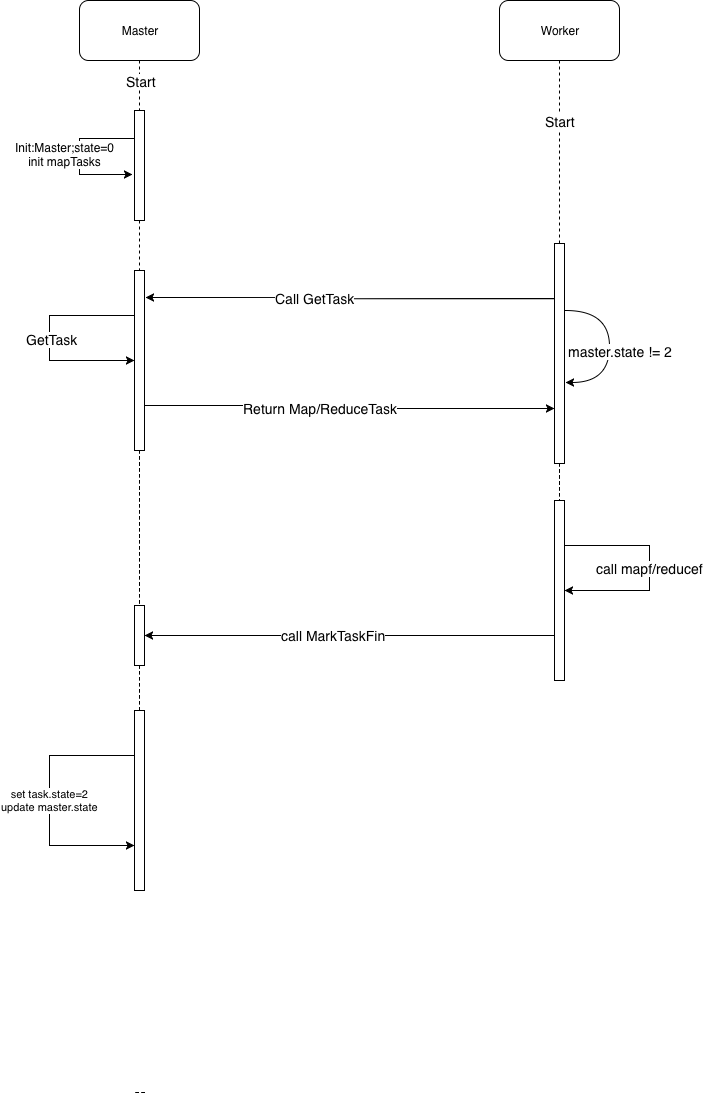
1、启动Master后,Master状态为INIT,并根据启动参数初始化map任务
2、启动Worker,请求Master分配一个任务,然后处理任务(map/reduce)
3、处理完成后通知Master更新任务状态为完成;每次有任务完成时,检查Map/Reduce任务是否全部完成,根据完成进度更新Master状态
4、所有任务完成后,Master状态为REDUCE_FINISHED
崩溃处理
关于处理worker崩溃,实验提示里提到,Master不能明显区分出Worker是处理超时还是崩溃了,所以需要设计一个超时时间(如10秒),如果任务超时了,就认为任务未完成,下一次再重新分配。实现是在Master分配一个任务时,初始化一个开始时间,Master分配任务时,检查进行中任务,如果任务还未完成且超时了,就重新分配该任务给Worker。
ALL PASS
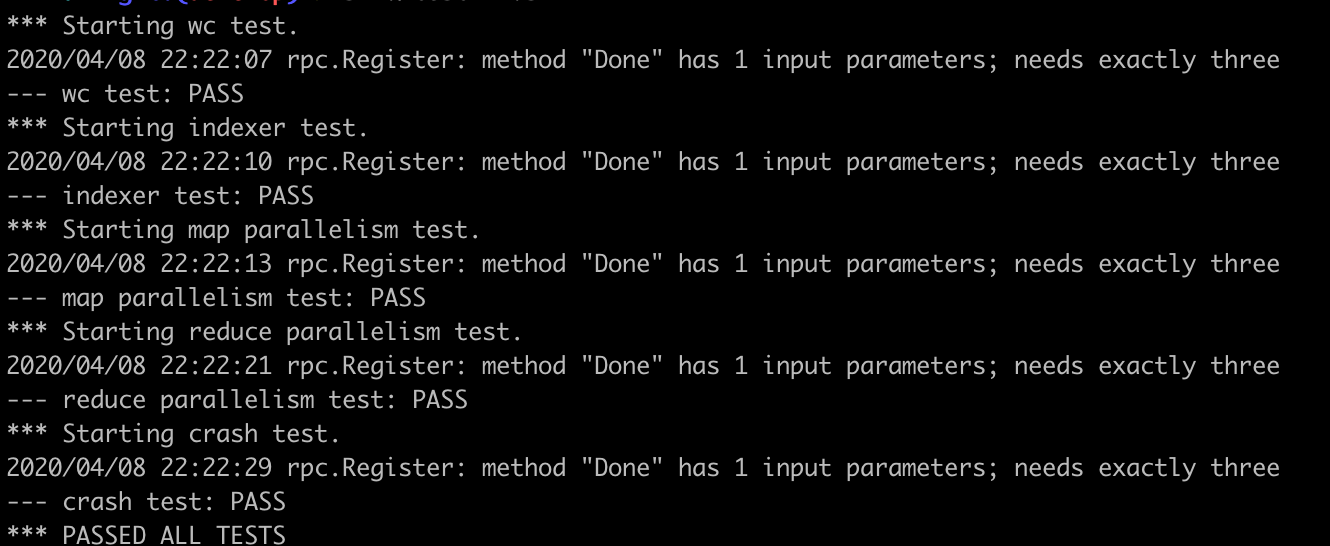
所有测试用例都通过的那一刻,内心有一份小小的激动,仿佛上大学时通过了一道实验题那种感觉。
Q&A
分享几点学习中遇到的问题:
1、学习这个有什么用?
这个问题比较尖锐了,我的理解就是,如果对分布式系统感兴趣,想通过实践来强化对分布式系统的理解,那么学习这个课程会有帮助。如果不感兴趣的话,那么这篇文章对你没有什么用。
2、如何开始学习?
看课程主页,根据课程表安排,先看论文,在看视频,理解个大概后开始做实验,然后再看论文和视频加深理解。
3、看完了视频,实验程序怎么跑起来?怎么开始写下第一行代码?
准备一点Go语言的基础,开始做时多看题目的提示,比如提示的第一点说到,让代码跑起来的第一步就是修改mr/worker.go的Worker函数,发一个RPC请求到Master,请求一个任务数据。
4、论文、课程和题目都是英文版的,看不懂怎么办?
硬着头皮看,不懂的就去翻译,当然可以看中文版,网上有很多资源。课程视频有热心网友做了个中文字幕,可以看中文字幕。
另外,多说一句,还是推荐尽量看英文版的,并没有崇洋媚外的意思,只不过对于程序开发而言,英文能力还是一个必备技能,因为平时查问题的时候都是英文资料比较多,而且读一手的资料是最好的,这篇文章也只不过是我消化完的知识分享,有可能论文和课程里还有很多我看不到但是你看得到的东西。
5、有代码链接吗?
程序员名言:talk is cheep, show me the code.但是由于课程强调了尽量不要看别人的实现,也有人放到Github被MIT要求删除过,所以笔者就不共享全部代码了,如果有需要可私下交流。
总结
通过学习前两课,完成MapReduce这个实验,对分布式系统有了一个最表面的认识,还谈不上掌握,这只是一个最简单的实验,更重点的课程和实验还在后面,路漫漫其修远兮。
如果你也在学习,希望这篇文章对你有帮助。欢迎有兴趣的同学来一起学习讨论。
原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
如果本文对你有帮助,请点个赞吧,谢谢^_^
