[Redis源码阅读]redis对象
结构定义
在redis中,对象的数据结构定义如下:
typedef struct redisObject { unsigned type:4; unsgined encoding:4; unsigned lru:LRU_BITS; int refcount; void *ptr; }
结构定义中的type:4、encoding:4这种定义方式称为**位段类型**。
使用位段类型的好处就是避免浪费内存,如果使用
unsigned int type定义type字段,需要4个字节,而使用unsigned type:4,只需要4个位段就足够了。
参数说明
redis对象有许多特性,比如:类型检查(通过type实现)、命令多态(encoding实现)、内存共享(通过refcount实现)等等,这些特性都是通过redisObject中的参数实现的。
type
对象类型,它的取值范围有五个,分别是redis使用的五种对象类型:
#define OBJ_STRING 0#define OBJ_LIST 1#define OBJ_SET 2#define OBJ_ZSET 3#define OBJ_HASH 4
在执行命令前对type字段进行检查,可判断出对象是否是命令允许执行的对象类型。
encoding
对象使用的编码类型,它的取值范围有下面这些:
#define OBJ_ENCODING_RAW 0 /* 动态字符串 */#define OBJ_ENCODING_INT 1 /* 整数 */#define OBJ_ENCODING_HT 2 /* 哈希表 */#define OBJ_ENCODING_ZIPMAP 3#define OBJ_ENCODING_LINKEDLIST 4 /* 旧的列表编码,现在不再使用了 */#define OBJ_ENCODING_ZIPLIST 5 /* 压缩表 */#define OBJ_ENCODING_INTSET 6 /* 整数集合 */#define OBJ_ENCODING_SKIPLIST 7 /* 跳跃表 */#define OBJ_ENCODING_EMBSTR 8 /* 用于保存短字符串的编码类型 */#define OBJ_ENCODING_QUICKLIST 9 /* 压缩链表和双向链表组成的快速列表 */
在调用命令的时候,redis还会根据对象使用的编码类型来选择正确的底层对象,执行对应函数的实现代码。
lru
最近最后一次被命令访问的时间 或者 最近最少使用的数据。
在执行OBJECT IDLETIME命令时,通过当前时间减去lru属性的值,得到键的空转时长。另外,如果服务器打开了maxmemory选项,且使用的内存回收算法是volatile-lur或者allkeys-lru,那么当服务器占用的内存超过了maxmemory的上限值,空转时长较高的键会优先被服务器释放,从而回收内存。
refcount
对象的引用计数。
redis的对象共享和内存回收特性就是通过refcount属性来实现,通过将refcount + 1实现对象共享;进行内存回收检查时,检查refcount == 0的对象,将对象进行回收。
ptr
指向底层数据结构用于保存数据的指针。
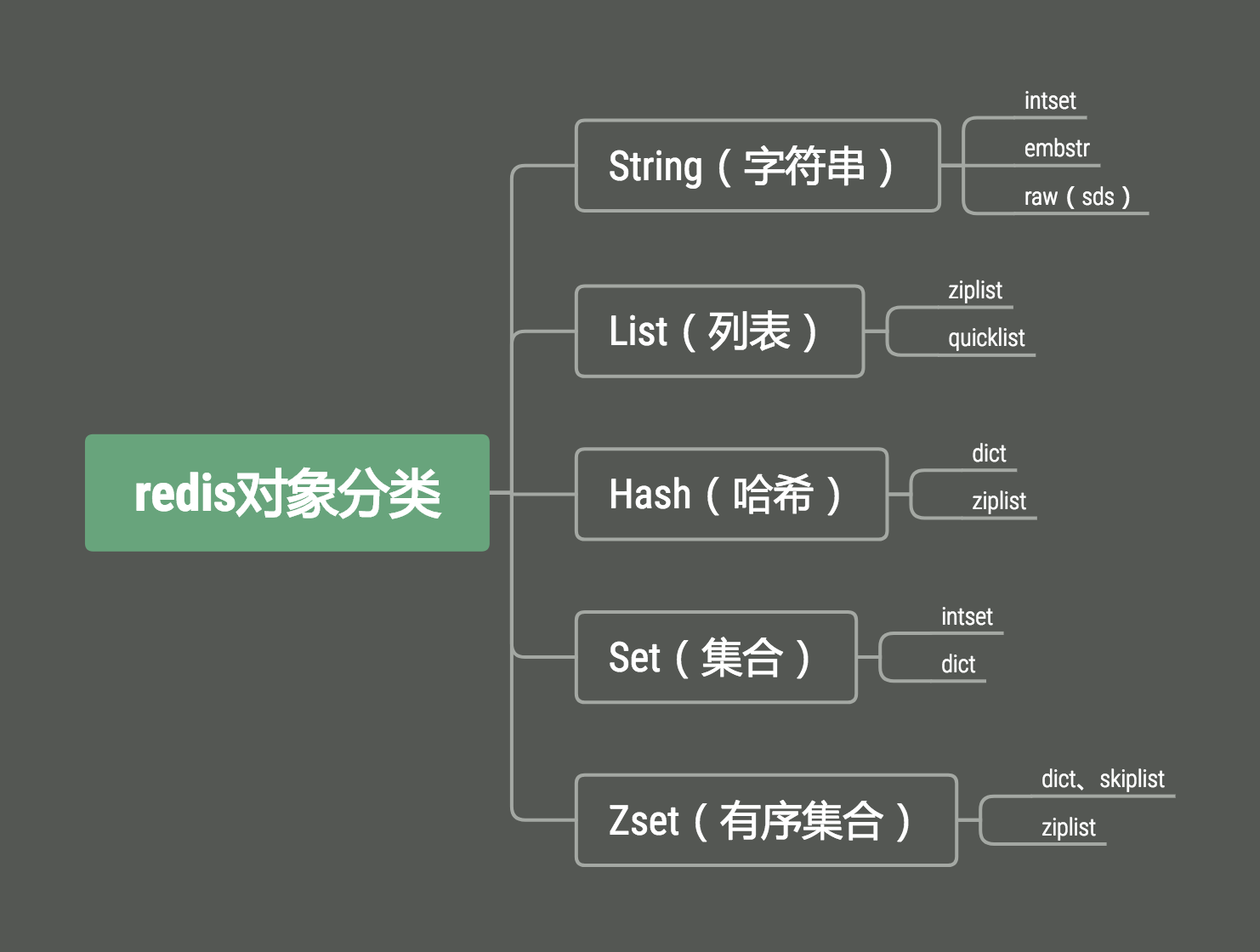
对象使用的数据结构
redis有五种对象,不同对象可能用到的数据结构如下图所示:
编码转换与命令多态
同一种对象使用不同的数据结构是通过encoding来实现,而且,同一个命令的实现方法会根据对象的编码属性而变化,这是命令的多态实现。 以哈希对象为例看看编码转换以及命令多态等特性是怎么实现的。
哈希对象
哈希对象使用的编码有:ziplist、hashtable。
如果使用压缩表作为底层实现,每当有新的键值对需要加入哈希对象,会先添加键节点到链表,然后添加值节点。
使用hashtable作为底层实现,每一个新的键值对都会使用字典键值对来保存,键和值分别是字符串对象。
使用不同结构保存后的结构图如下所示:
ziplist编码

hashtable编码
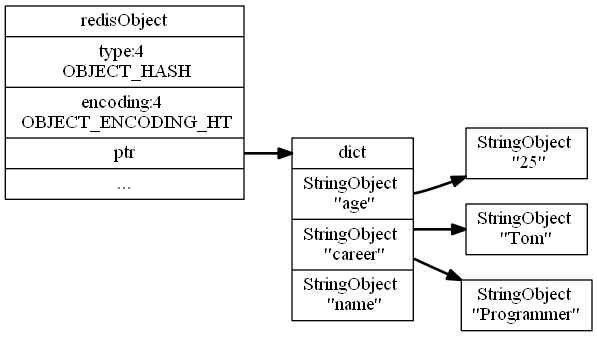
编码转换
每一种对象在使用编码的时候都有一定的条件,使用ziplist编码的哈希对象都应该满足两个条件:
- 1、所有键值对的键和值字符串对象长度小于64字节
- 2、哈希对象保存的键值对数量小于512个
如果不能满足上述条件时,redis会进行对哈希对象底层数据结构进行从压缩表到字典的转换,实现步骤是遍历压缩表,获取压缩表中的键和值,使用得到的键和值创建一个字典对象,然后添加字典里,具体代码如下:
hashTypeIterator *hi; dict *dict; int ret;
// 创建遍历器对象和哈希表 hi = hashTypeInitIterator(o); dict = dictCreate(&hashDictType, NULL);
while (hashTypeNext(hi) != C_ERR) { sds key, value;
// 用获取ziplis中的key、value新增键值对到哈希表 key = hashTypeCurrentObjectNewSds(hi,OBJ_HASH_KEY); value = hashTypeCurrentObjectNewSds(hi,OBJ_HASH_VALUE); ret = dictAdd(dict, key, value); if (ret != DICT_OK) { serverLogHexDump(LL_WARNING,"ziplist with dup elements dump", o->ptr,ziplistBlobLen(o->ptr)); serverPanic("Ziplist corruption detected"); } } hashTypeReleaseIterator(hi); zfree(o->ptr); o->encoding = OBJ_ENCODING_HT; o->ptr = dict;
命令多态
命令多态是检查对象的编码,然后执行不同的实现方式。比如哈希对象中的hget命令。
hget命令实现代码:
void hgetCommand(client *c) { robj *o;
// key不存在,返回空 if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.nullbulk)) == NULL || checkType(c,o,OBJ_HASH)) return;
addHashFieldToReply(c, o, c->argv[2]->ptr); }
hget命令的实现最终是调用addHashFieldToReply函数(代码如下),该函数是通过判断哈希对象的编码来决定使用什么函数来获取哈希对象具体field的值,其他命令的实现也是大同小异。
static void addHashFieldToReply(client *c, robj *o, sds field) { int ret;
if (o == NULL) { addReply(c, shared.nullbulk); return; }
// 根据底层不同编码获取field的值 if (o->encoding == OBJ_ENCODING_ZIPLIST) { unsigned char *vstr = NULL; unsigned int vlen = UINT_MAX; long long vll = LLONG_MAX;
ret = hashTypeGetFromZiplist(o, field, &vstr, &vlen, &vll); if (ret < 0) { addReply(c, shared.nullbulk); } else { if (vstr) { addReplyBulkCBuffer(c, vstr, vlen); } else { addReplyBulkLongLong(c, vll); } }
} else if (o->encoding == OBJ_ENCODING_HT) { sds value = hashTypeGetFromHashTable(o, field); if (value == NULL) addReply(c, shared.nullbulk); else addReplyBulkCBuffer(c, value, sdslen(value)); } else { serverPanic("Unknown hash encoding"); } }
总结
redis中的很多操作都是基于上面介绍的redis对象,了解这些对象的底层实现,可以为之后更多的redis特性做准备。
原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
